[CS] 아스키 코드와 유니코드
아스키코드 (ASCII Code)
아스키 코드의 등장
사람은 IO Device(Input Output Device)와 사람이 쓰는 문자로 소통한다. 하지만 컴퓨터는 이진수 외에는 들어 갈 수 없기 대문에 데이터를 저장하는 방법이 있어야 한다. CPU와 메모리는 계산만 하기 때문에 필요가 없다.우리가 쓰는 문자를 이진수로 받아들이도록 문자를 숫자에 지정해야 했다. 여기서 세계 표준 코드가 나오는데 그게 바로 아스키 코드이다.
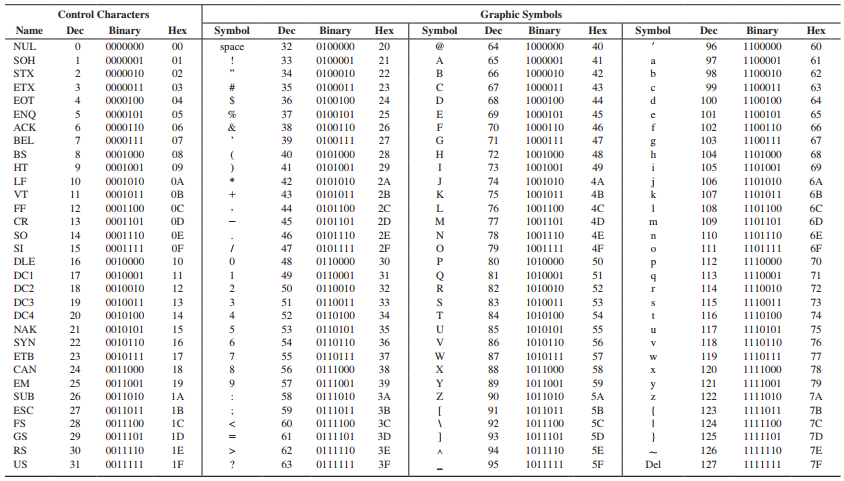
아스키코드의 구성
Bit는 가장 작은 정보의 단위다. Byte는 8bit이고 256가지의 경우의 수가 나온다. 아스키 코드는 127개로 구성되어 있으므로 7비트를 사용한다. 1비트를 추가하면 외국어 등 추가적인 문자를 사용할 수 있도록 하였다. 이렇게 총 8비트 형식으로 아스키코드를 나타낸다. 하지만 중국어와 같이 아스키 코드로 다 표현할 수 없는 언어들이 있는데 이를 위해 유니코드가 나왔다.
유니코드 (Unicode)
유니코드란
유니코드는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이다. 유니코드는 2byte에서 4byte 사이로 가변적이다. 유니코드는 기본적으로 2 바이트로 한 문자를 표현하여, 기존 7 비트 또는 8 비트로 한 문자를 표현하는 아스키 문자 기반 시 스템과 호환을 위해 UTF를 사용한다.
유니코드 변환 형식
UTF-8은 모든 유니코드 문자를 1~4바이트의 8비트 단위로 인코딩한다. 유니코드 문자 모드를 인코딩하며 가장 많이 사용되는 방식이다.
UTF-16은 2 바이트(16 비트) 단위로 1~2개를 사용하여 유니코드의 유효한 모든 문자를 인코딩할 수 있다. 자바 프로그래밍에서 기본으로 사용된다.
UTF-32는 유니코드 문자를 모두 4 바이트(32 비트)고정 길이로 인코딩하며, 인코딩 변환 처리가 따로 필요 없다.
*학과 수업 내용을 바탕으로 작성되었습니다